
NooJ
A Corpus Processor - A Linguistic Development Environment - A Linguistic Engine for developing Natural Language Processing software Applications.

1991-1997: Max Silberztein developed the linguistic platform INTEX (v1-v3) for the NextStep Operating System at the LADL laboratory of the Université Paris 7, using the Objective-C programming language. After 1997, he developed INTEX (v4-v5) for the Windows Operating System at the LASELDI laboratory of the Université de Franche-Comté in C++. Before leaving to the USA for three years, he entrusted the INTEX sources and linguistic resources to Maurice Gross (University Paris 7).
After M. Gross's death and during Max Silberztein's absence in the USA, Sébastien Paumier, under the supervision of Eric Laporte, "developed" Unitex at the Université Marne-La-Vallée with funding from the ANR French National project OUTILEX, without Max Silberztein's consent, nor even his knowledge nor his employer's, the Université de Franche-Comté. Neither Sébastien Paumier, nor Eric Laporte, nor Mathieu / Matthieu Constant, nor Denis Maurel, nor any member of the Université de Marne-La-Vallée, nor any employee of the companies of the OUTILEX consortium, had ever participated in the development of INTEX.
Unitex constitutes the essential of Sebastien Paumier's thesis "De la reconnaissance des formes linguistiques à l'analyse syntaxique", which was defended in July 2003 at the Université de Marne-La-Vallée. Eric Laporte (Advisor), Christian Choffrut, Franz Guenthner, Jee-Sun Nam et Dominique Perrin who all knew the INTEX software very well, validated the thesis nonetheless.
In 2002, two experts from the Agence pour la Protection des Programmes (the Copyright French National Agency) asserted that Unitex is neither a new software "inspired" by INTEX, nor a "clone", nor even a "legitimate" piece of work: it is just INTEX, renamed. See following link for the legal definition of counterfeit in France:
http://www.app.asso.fr/centre-information/base-de-connaissances/code-logiciels/la-protection-du-logiciel/agir-contre-les-atteintes
Certain people justify the Unitex operation with the argument that INTEX was a “closed" software sold to companies, whereas Unitex is an “open” software, free for all. These people forget to mention that they had access to INTEX’s complete source, and that neither INTEX’s author nor his employer (Université de Franche-Comté) had been involved in any INTEX sale, nor even in the well funded Outilex ANR project.
Unitex's real author is Max Silberztein; however, the scientific publications, the national and international projects, as well as the universities, research centers and private companies who are using Unitex never acknowledge it. Please do not encourage any project based on Unitex, nor its sycophants.
Short extract of the Unitex analysis report, published since 2002 at the INTEX page of the Université de Franche-Comté Web site (never contradicted):
1. Linguistic Resources
The way INTEX represents grammars graphically is an original invention, presented in:
Max Silberztein, 1993. Dictionnaires électroniques et analyse automatique de textes : le système INTEX. Masson Eds: Paris.
Max Silberztein has replaced finite-state automata's states and transitions with nodes; only one initial node and one terminal node are allowed; outputs of finite-state transducers are displayed in bold under nodes, clickable auxiliary nodes refer to embedded graphs; unconnected nodes are treated as comments, etc. These conventions are exactly the same in Unitex.
A number of linguistic resources were stolen from the INTEX package and even commented in the Unitex documentation without their author's consent nor even any citation, e.g.:
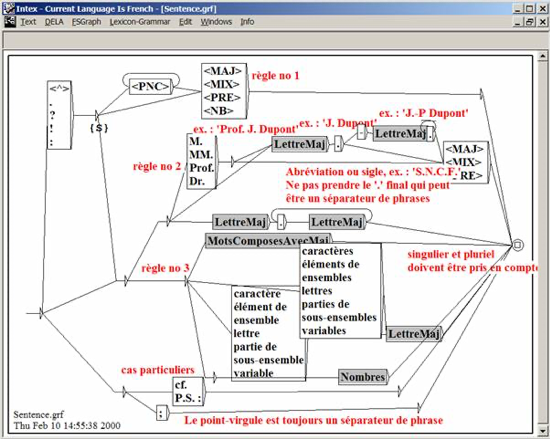
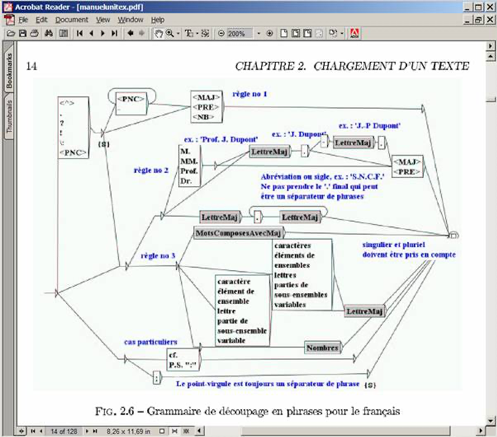
Figure 1. INTEX Unitex
Notes (such as “Règle no 1” [Rule #1]) are discussed in the INTEX manual... but are nowhere mentioned in the Unitex manual (even though they were left in the Unitex "version" of the grammar).
The red colour in INTEX became blue in Unitex, which is inconsistent with Unitex parameters (see Fig. 7). C++ and JAVA use inverted byte-orders to represent RGB colors: this mistake proves that Sébastien Paumier and Eric Laporte converted INTEX C++ sources into Java to construct Unitex, without paying attention.
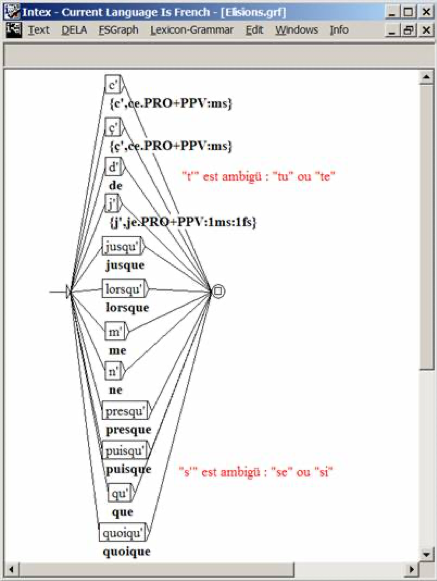
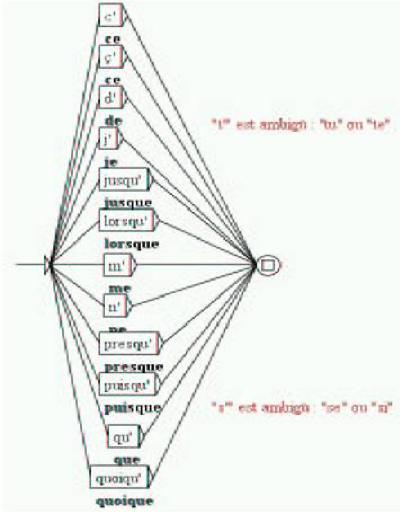
Figure 2. INTEX Unitex
The figure presented in the Unitex manual is a cropped screenshot of INTEX (with the correct coloring). This proves that Sébastien Paumier had INTEX installed on his PC and running when he wrote Unitex manual.
2. Interface and Functionalities
The two software have the exact same functionalities that are unique and cannot be found in any other software at the time, and they share an almost identical user interface, e.g.:
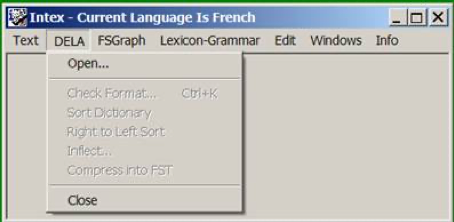
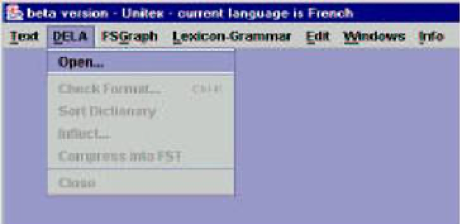
Figure 3. INTEX Unitex
In Windows applications, the Edit menu is located at the second left position (right after File/Text). There is no way Unitex would make the same mistake as INTEX independently, unless of course it is a just a quick copy.
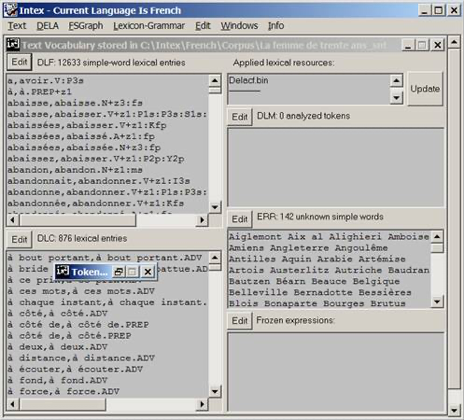
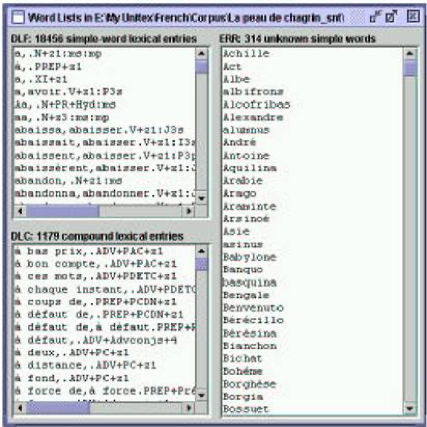
Figure 4. INTEX Unitex
The Unitex presentation of results is a partial copy of INTEX's. As Unitex does not display what lexical resources were used to process the text, the list of unrecognized words is useless: Sébastien Paumier and Eric Laporte copied INTEX' interface without fully understanding what INTEX was displaying, and why.
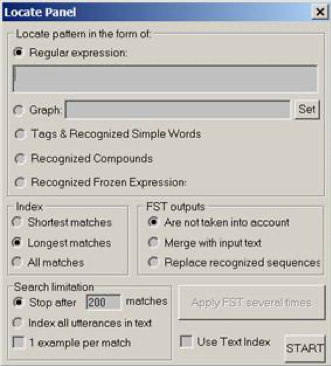
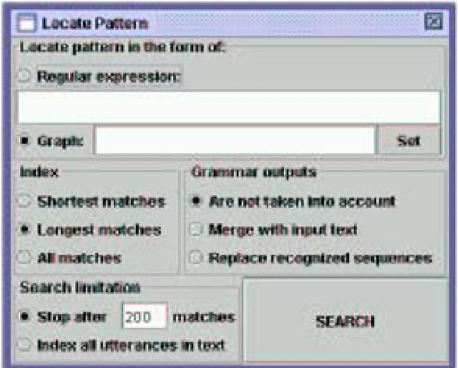
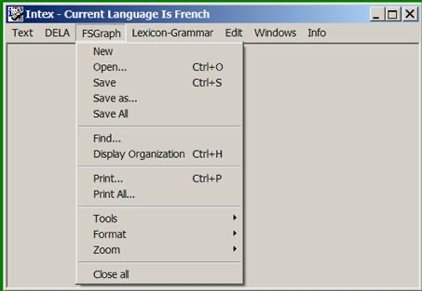
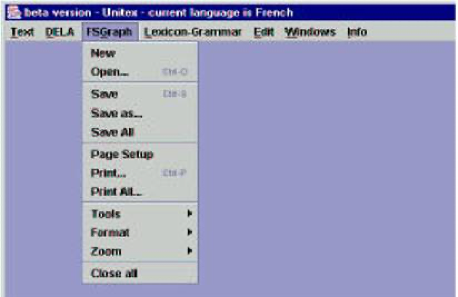
Figure 5. INTEX Unitex
The menu item "FSGraph" corresponds to INTEX's FSGraph graphical editor. Sébastien Paumier kept this menu name in Unitex, even though Unitex's graphical editor was renamed "Unigraph" (as seen in Fig. 11). This mistake proves again that Unitex is just a quick copy of INTEX's.
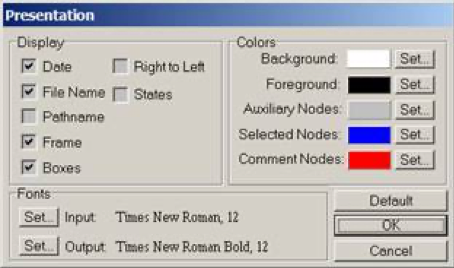
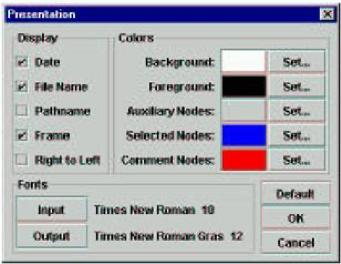
Figure 6. INTEX Unitex
The presentation options are exactly the same but are not consistent in Unitex: for instance, "Comment nodes" are displayed in blue (not in red), as seen in Fig. 1.
Figure 7. INTEX Unitex
3. Methodology
All the methods used to perform the various levels of lexical and morphological analyses of texts, as well as the representation of intermediate results and analyses, are identical in the two software:
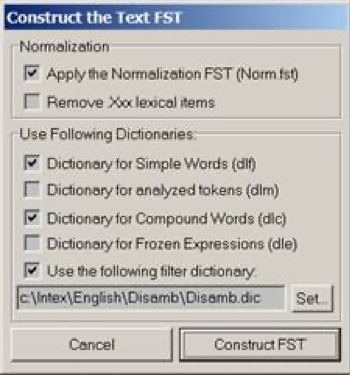
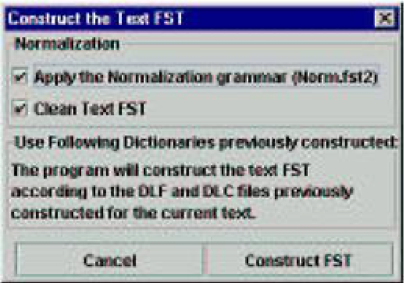
Figure 8. INTEX Unitex
The differences in presentation are superficial: "Remove Xxx lexical items" is functionally exactly the same as "Clean Text FST", and INTEX's check boxes (e.g. dlf and dlc) were replaced with a label (where dlf corresponds to DLF and dlc to DLC).
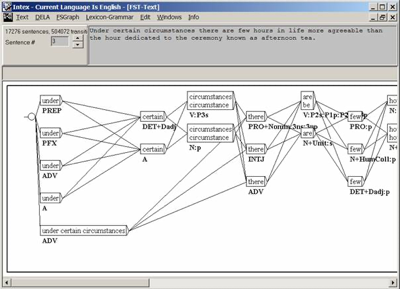
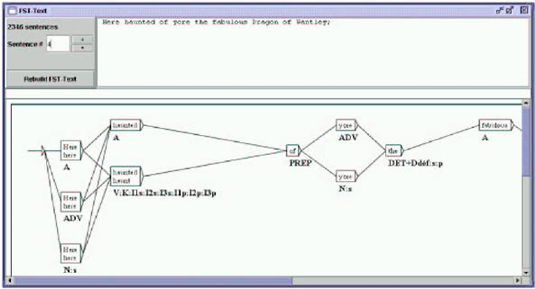
Figure 9. INTEX Unitex
INTEX and Unitex represent the result of the lexical analysis exactly in the same manner: in the form of a finite-state graph, in which each lexeme is represented in a node. The mini difference in background color is meaningful in INTEX: the text is read-only (hence grayed out), whereas the graph can be edited (hence white); in Unitex however, the text's background is white, even though it cannot be edited.
The tools used to process inflectional morphology, as well as their resources and their internal representation, and the way they look, are the same, e.g.:
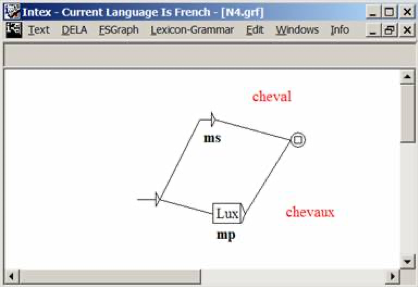
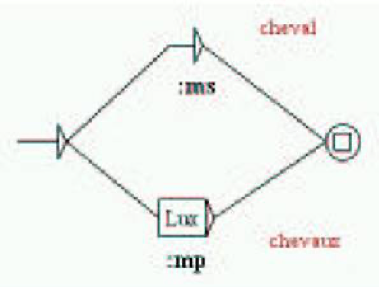
Figure 10. INTEX Unitex
Here too, the Unitex manual contains a cropped screenshot of INTEX, which proves that Sébastien Paumier had INTEX opened on his PC while he was writing Unitex's manual. Symbols and code formats used in morphological and syntactic grammars are identical; dictionary maintenance tools are identical (sometimes renamed, such as “recondic” renamed as “checkDic”); Unitex uses the exact same algorithms as INTEX to sort dictionaries even though Unitex should not need to, since it uses Unicode characters; Dictionaries are managed the same way (e.g. 3 levels of priority), and applied the same way to texts, in the same step.
4. Programs, Algorithms and File Formats
The two software use the same programs, used the same way and constructed on the same algorithms, with transparent modifications, e.g. replace “char” with “wchar”; convert C++ source code in Java, etc.
Several Unitex functionalities can only be explained by the fact that Unitex is a quick copy of INTEX. For instance, INTEX needs to allow users to describe lexicographic orders for each language. As Unitex is using the Unicode standard (which includes support for lexicographic orders), it should not need INTEX's complicated set of methods. Why then does Unitex use the same exact method as INTEX to manage lexicographic order, rather than simply drop them in favour or Unicode? Obviously, this is because Unitex is just a copy of INTEX.
File format are either identical, or almost identical, e.g.:



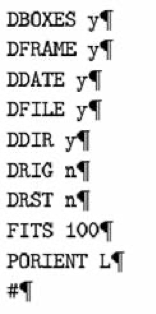
Figure 11. INTEX Unitex
The header “FSGraph” (name of INTEX's graph editor) has been replaced with the header “Unigraph” in all the linguistic resources's files distributed in the Unitex package, even though they had been developed with INTEX.
The order of the parameters used to describe INTEX graphs (DBOX, DFRAME, DDATE, etc.) is not relevant. The fact that they are not in alphabetical order (e.g. DFRAME before DDATE) and still identical in INTEX and Unitex, can only be explained by the fact that the Unitex author just copied the INTEX sources.
Unitex’s GUI still kept the menu item “FSGraph” (as seen in Fig.5), even though it is now supposed to be "Unigraph".
5. Conclusion
See the statement from the Claude Condé, Dean and Jean-Marie Viprey, member of the Scientific committee of the Université de Franche-Comté:
A l’automne 2002, la communauté scientifique a vu apparaître, sur le site de l’Institut Gaspard-Monge de l’Université de Marne-la-Vallée, un nouveau logiciel de reconnaissance linguistique nommé Unitex, signé de M. Sébastien Paumier sous la responsabilité du Pr. Eric Laporte.
Tout chercheur ou usager familier du logiciel INTEX, créé par Max Silberztein d’abord au LADL (CNRS-Univ. Paris 7), puis depuis 1997 à l’Université de Franche-Comté, a constaté que la méthodologie, l’architecture, les programmes, l’interface utilisateur et la documentation d’ Unitex sont quasi-identiques à celles d’INTEX. De plus, de nombreux fichiers (dictionnaires et graphes, etc.), ont été inclus dans l’ensemble Unitex, malgré l’interdiction sur le site WEB d’INTEX : “None of the programs and linguistic resources included in the INTEX package should be copied, redistributed, incorporated into other software, or published without their author’s consent and proper citation.”
L’apparition d’Unitex soulève de nombreuses questions. Quel intérêt peut avoir un laboratoire associé au CNRS de publier un doublon périmé d’INTEX, alors que ses membres concernés, à commencer par M. Paumier lui-même, appartenaient à la communauté INTEX, comme le montre bien leur participation régulière aux Journées INTEX, jusqu’en mai 2002 à Marseille ? Rappelons que l’Université de Marne-la-Vallée utilisait intensivement INTEX pour ses besoins en Enseignement comme en Recherche.
Si, comme on l’a entendu dire, il s’agissait de dépasser certaines limitations d’INTEX en matière de portabilité, pourquoi ne pas avoir soulevé ce problème ouvertement dans la communauté INTEX, voire dans la communauté TAL tout entière ? Où sont les traces de la discussion, et de l’échec de cette discussion, qui justifierait la rupture inamicale et violente que représente le surgissement d’Unitex ? Pendant plusieurs mois, le nom même d’INTEX ou de son auteur ne figurait pas, ni dans la documentation, ni sur aucune des pages WEB liées à Unitex.
Notre point de vue est explicite : INTEX a été conçu par le Pr. Max Silberztein à l’Université Paris 7, et est développé depuis 1997 à l’Université de Franche-Comté. Nous sommes prêts à discuter, dans quelque cadre public que ce soit des raisons qui ont poussé MM Laporte et Paumier à considérer qu’ils avaient le droit de construire une copie d’INTEX et de la présenter comme un travail original. Nous sommes toujours, avec la direction de notre Université, à la recherche d’un arbitrage scientifique.
En attendant, nous tenons à bien clarifier ce point aux yeux des chercheurs et utilisateurs : paradoxalement, si Unitex apparaît bien comme étant largement une copie d’INTEX, l’avenir de ces deux logiciels est antagonique. Le traitement de la communauté scientifique par l’équipe de Marne-la-Vallée laisse entrevoir une conception très particulière de l’activité scientifique, et de la mission des enseignants-chercheurs.
— Pr. Claude Condé
Head of the SLHS Department (Arts and the Humanities) of the Université de Franche-Comté.
— Pr. Jean-Marie Viprey
Scientific Committee of the Université de Franche-Comté.
**********
Unitex's interface, methodology, file formats, functionalities and programs as well as its inconsistencies and useless functionalities prove that Unitex was written quickly by someone who had full access to INTEX sources, and copied them without always understanding what he was doing.
If you are still interested in using Unitex and support its promoters, you may have fun playing at "Spot the difference" by looking at INTEX manual:
Silberztein, M. (2000). INTEX Manual. available at http://intex.univ-fcomte.fr (230 pages).
If you would rather pass, check out the NooJ linguistic platform, which implements an original and innovative methodology backed by powerful computational algorithms, described in:
Silberztein, M. (2015). La formalisation des langues : l’approche de NooJ. ISTE Ed.: Londres. (429 pages).
Silberztein, M. (2016). The Formalisation of Natural Languages: the NooJ approach. Wiley Eds.: Hoboken NJ, USA (346 pages).
NooJ is free and GPL open source, endorsed and distributed by the European Community (Metashare program), is used by over 100 honest researchers in the world to describe over 30 languages, and contains over 20 linguistic, computational and statistical functionalities that make it objectively more technically and scientifically valuable than Unitex:
- NooJ represents texts in UTF8, which is more efficient than Java UTF16
- NooJ manages equivalent characters, absent diacritics (e.g. in Arabic), ligatures (e.g. "oe" = "œ") and Unicode combined characters
- NooJ corpus processor handles over 150 file formats, including XML, PDF, WORD, etc.
- NooJ does not need to produce DELAF- nor DELACF-type dictionaries; this is crucial for heavy-morphology languages such as Hungarian
- NooJ dictionaries handle spelling variants and synonyms in a unified way
- NooJ dictionaries handle simple words, contracted words (e.g. "can't") and multiword units (e.g. "as a matter of fact") in a unified way (no need to separate simple words from multiwords)
- NooJ dictionaries can represent multilingual information accessible from any grammar (that allows for easily written MT systems)
- NooJ handles lexicon-grammars by pairing dictionaries and grammars without compiling gigantic finite-state automata
- NooJ dictionaries are represented by machines that are neutral vis-à-vis Parsing/Generation applications and can even be mixed (crucial for paraphrase generation).
- NooJ represents all text analyses in a Text Annotation Structure which allows for efficient cascades and linguistically-natural grammars
- TAS may represent lexical, morphological, syntactic or semantic (unsolved) ambiguities; all NooJ parsers can manage ambiguous TAS
- in the TAS, annotations might be discontiguous, e.g. 1 single annotation for "turn off" in "They turned the light off."
- NooJ unifies Inflectional and Derivational grammars
- NooJ inflectional and derivational grammars for simple words are reused to describe multiword units (w/wout agreement constraints)
- NooJ morphological engine uses programmable operators that can be adapted to or added for any language
- NooJ can process Agglutination morphology; this is crucial for Germanic and Semitic languages
- NooJ grammars are embedded sets of graphs, which allows teams to share resources with no risk of conflicts
- NooJ processes Context-Sensitive Grammars like LFG; this is crucial for Slavic languages
- NooJ processes Unrestricted Grammars like HPSG; this is crucial for languages with unordered syntax such as Hungarian
- All NooJ grammars can be described either by rules entered in a text editor, or graphically using a graphical editor
- NooJ contains a set of unique maintenance tools for its linguistic resources, e.g. contracts
- NooJ syntactic parser transparently processes agglutinated and contracted words as well as multiwords and discontiguous expressions
- NooJ parser can produce and display graphically derivation trees, e.g. Main(NP(ProperName "John")) V(SingleVerb("ate"), NP(Det(two) Noun(apples)))
- NooJ parser can produce and display graphically constituent trees, e.g. Sentence (NP(John), V(ate), NP (two apples))
- NooJ parser can produce and display graphically dependency trees, e.g. eat (John, apple (two))
- NooJ includes several disambiguation tools: local grammars, negative grammars, global grammars and contains a powerful annotation management system
- NooJ's Transformational engine can produce paraphrases, perform automatic generation, Machine Translation, etc.
- NooJ contains various statistical tools used in the Digital Humanities (vocabulary frequency, normal distribution, standard score, tf-idf, etc.)
- etc.